About
BON in a Box serves as a hub for Biodiversity Observation Networks (BONs), consolidating diverse tools and resources to enhance data analysis and collaboration, as well as a project catalogue. For more information about BON in a Box in general, please refer to BON in a Box’s website. For more details on the rationale supporting the pipeline engine, refer to our BioScience publication.
What is BON in a Box’s pipeline engine?
BON in a Box now provides an open-source, fully transparent platform that allows users to contribute data and analysis pipelines to calculate indicators to assess progress towards biodiversity targets. BON in Box can integrate diverse data and expert knowledge, from Earth observation to genetic diversity metrics to calculate monitoring framework indicators.
We present here the BON in a Box pipeline engine as the ultimate ecosystem for harmonizing biodiversity observations, fostering efficiency, and amplifying the power of data-driven insights.
It is a community-contributed and open-source data to biodiversity indicator or data to Essential Biodiversity Variable (EBV) workflow repository curated by GEO BON. Its engine allows seamless connection of steps in different languages (R, Julia, Python) through a modular pipeline approach that analyzes both from user-provided and publicly available data sources. These pipelines combine local and global data sources in the EBV and biodiversity indicator calculations.
Why do we need this platform?
Scientists around the world are developing tools to create workflows to calculate essential biodiversity variables and indicators to report on biodiversity change. However, there are almost no platforms to share these workflows and tools, leading to duplication of effort. BON in a Box allows networks to share and enhance each other’s work.
Additionally, organizations often lack the technical capabilities to calculate these indicators to monitor biodiversity, which impairs decision-making. BON in a Box can bridge the gap between those knowing how to calculate, and those needing the indicators for monitoring and conservation.
What is a pipeline?
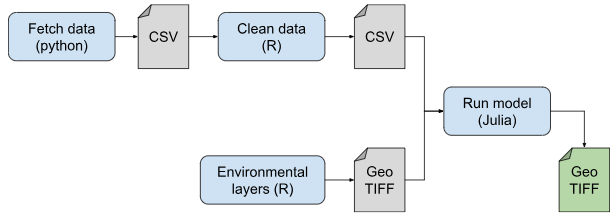
A pipeline is a collection of steps needed to transform input data into valuable output for the stakeholder in an automated way. It can be an EBV, an indicator, or anything useful for monitoring and decision-making in the context of biodiversity conservation and natural resource management.
The smaller steps composing a pipeline are scripts. These scripts also convert input data into valuable outputs, just like pipelines, but at a finer scale: cleaning, augmenting, standardizing, or performing statistical analyses. Importantly, these scripts can be reused or repurposed across varied contexts. For instance, data cleaning scripts could be applied to multiple pipelines that use similar types of data, enhancing efficiency and consistency in data processing workflows. Since the outputs are in-between every step, the pipeline can abstract the programming language, allowing a pipeline to mix R, python and Julia scripts without any interoperability issues.
If a pipeline builds upon the results of another pipeline, this “inner pipeline” can be included as a step in the “outer pipeline”; we call this a subpipeline. An SDM pipeline could serve to generate range maps inside a Species Habitat Index pipeline, or embedded in a Species Richness pipeline. We can thus define a step as “a script or a subpipeline performing an operation in the context of a pipeline”.
Why should you contribute?
Contributing to BON in a Box can increase the impact of your research by allowing your analysis workflows to be used in broader areas and contexts for decision-making. Contributors will become part of a global community generating analyses of the status and trends of biodiversity to inform management decisions.
How to cite
Please cite the BON in a Box platform as:
Jory Griffith, Jean-Michel Lord, Michael D Catchen, Maria Isabel Arce-Plata, F Guillaume Blanchet, Mathusan Chandramohan, M Camila Diaz-Corzo, Dominique Gravel, César Gutiérrez, Isabelle S Helfenstein, Sean Hoban, Jamie M Kass, Linda Laikre, Guillaume Larocque, Deborah M Leigh, Brian Leung, Alicia Mastretta-Yanes, Katie L Millette, Maria Alejandra Molina Berbeo, Dat Nguyen, Kari E Norman, María Helena Olaya-Rodríguez, Simon Pahls, Kaitlyn Pereira, Pedro R Peres-Neto, Timothée Poisot, Laura J Pollock, Juan Carlos Rey-Velasco, Victor J Rincon-Parra, Claudia Roeoesli, François Rousseu, Lina María Sánchez-Clavijo, Meredith C Schuman, Oliver Selmoni, Jessica M da Silva, Erika Suarez-Valencia, Thilina D Surasinghe, Eren Turak, Luis Fernando Urbina, Sarah Valentin, Noah Wightman, Juan Zuloaga, Maria Cecilia Londoño, Andrew Gonzalez, BON in a Box: An Open and Collaborative Platform for Biodiversity Monitoring, Indicator Calculation, and Reporting, BioScience, 2026, biaf189, https://doi.org/10.1093/biosci/biaf189